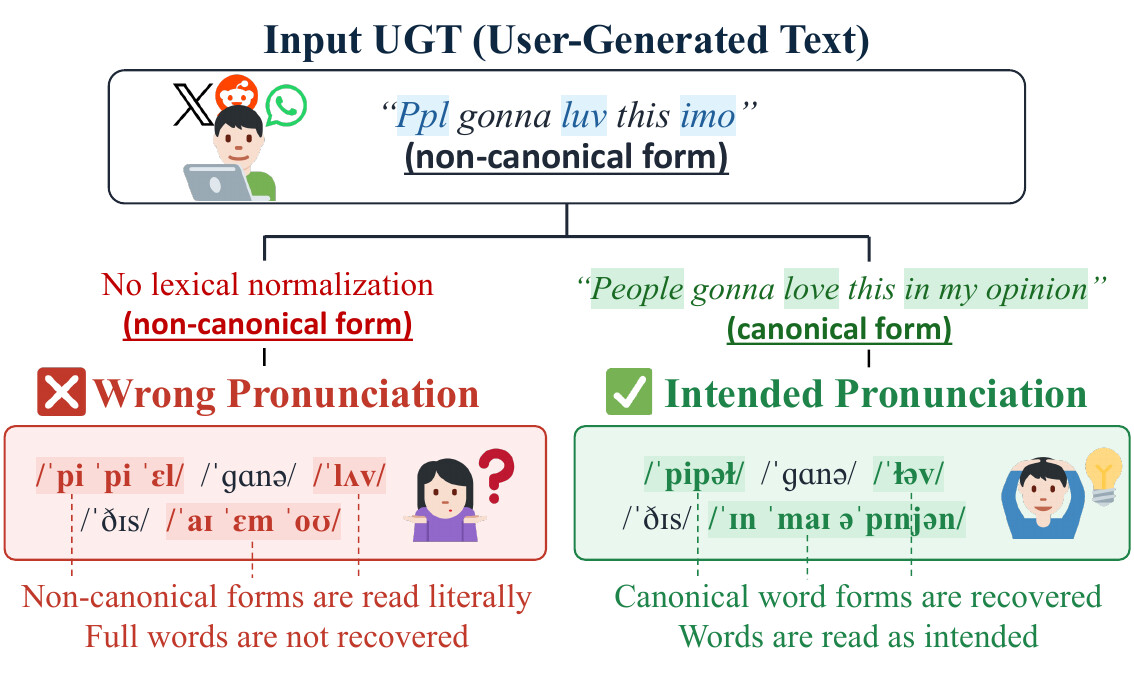
A benchmark and taxonomy for phonemizing noisy user-generated text, paired with a compositional approach that handles the irregular spellings, abbreviations, and code-mixing typical of real-world informal writing. The work provides both a standardized evaluation suite and a method that decomposes phonemization into reusable, robust components.
@inproceedings{jeon2026phonemizing,title={Phonemizing User-Generated Text: A Benchmark, Taxonomy, and Compositional Approach},author={Jeon, MinJu and Park, Younghan and Park, Han Sung and Kim, Jong-Hwan and Kim, Dong-Jin and Lee, Hoyeon},year={2026},note={Submitted to EMNLP 2026},status={preprint},}
Publications
2026
IEEE Access
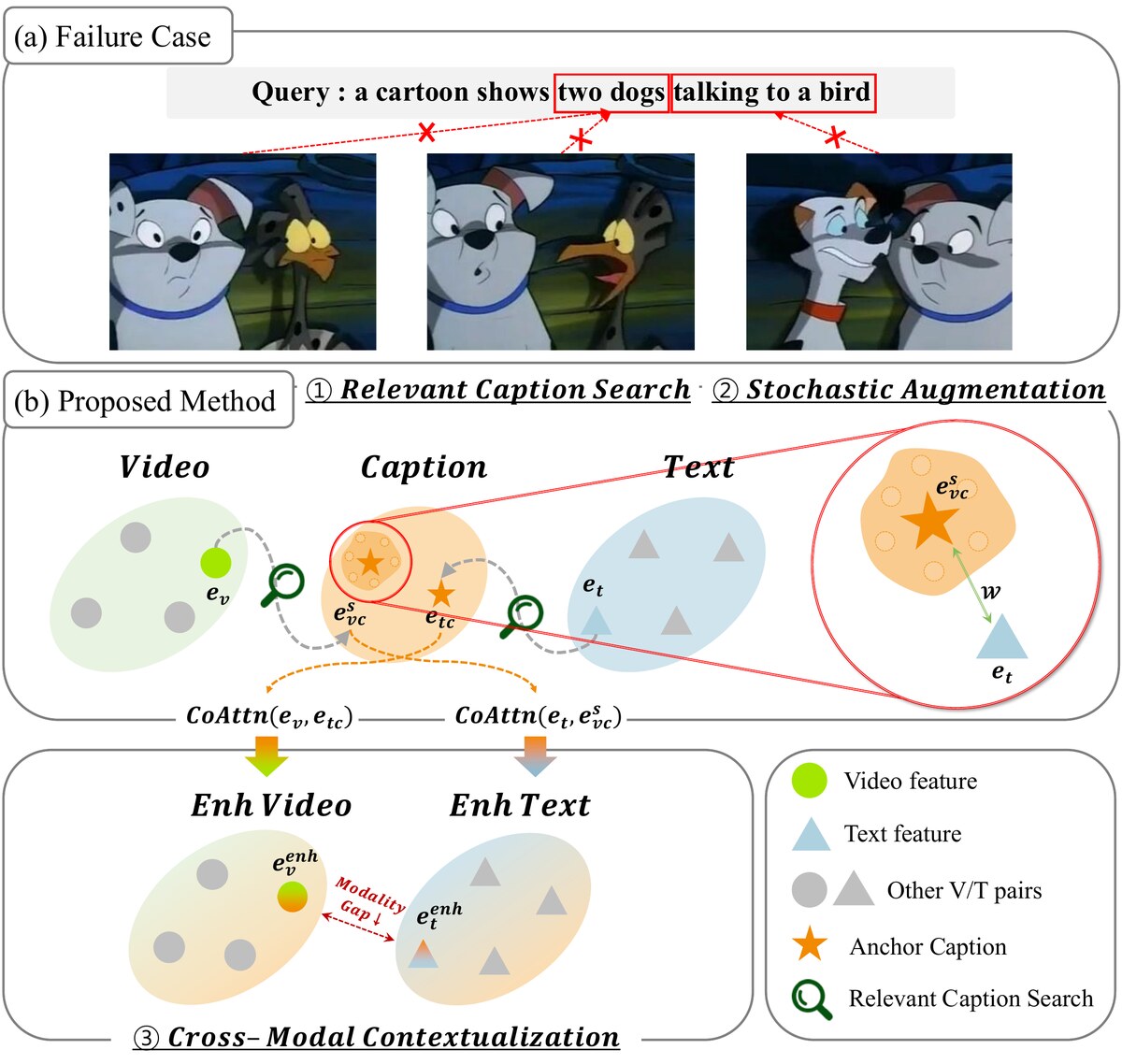
Cap4Bridge: Caption-Guided Cross-Modal Contextualization with Stochastic Augmentation for Text-Video Retrieval
MinJu Jeon, Hyungee Kim, Si-Woo Kim, Youngtaek Oh, Soeun Lee, and Dong-Jin Kim
Cap4Bridge bridges the text-video modality gap by using generated captions as cross-modal context, enriched through stochastic augmentation during training. The method improves robustness and generalization in text-video retrieval without requiring additional human supervision.
@article{jeon2026cap4bridge,title={Cap4Bridge: Caption-Guided Cross-Modal Contextualization with Stochastic Augmentation for Text-Video Retrieval},author={Jeon, MinJu and Kim, Hyungee and Kim, Si-Woo and Oh, Youngtaek and Lee, Soeun and Kim, Dong-Jin},journal={IEEE Access},year={2026},status={published},}
CVPR
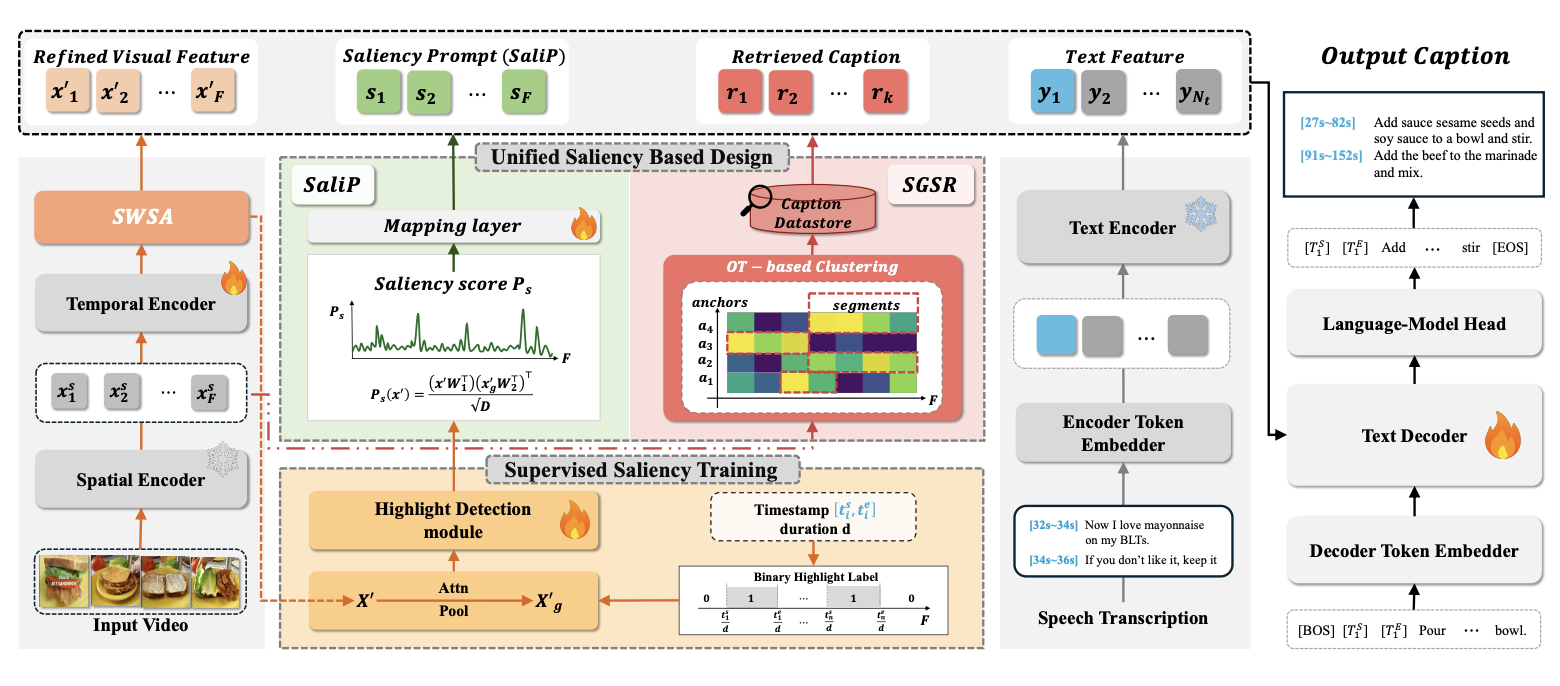
Follow the Saliency: Supervised Saliency for Retrieval-augmented Dense Video Captioning
Seunghee Choi, MinJu Jeon, Hyunwoo Oh, Jihwan Lee, and Dong-Jin Kim
A retrieval-augmented dense video captioning approach that injects supervised saliency signals into both the retrieval and generation stages. The saliency guidance helps the model focus on temporally important moments, producing more grounded and informative captions.
@article{choi2026follow,title={Follow the Saliency: Supervised Saliency for Retrieval-augmented Dense Video Captioning},author={Choi, Seunghee and Jeon, MinJu and Oh, Hyunwoo and Lee, Jihwan and Kim, Dong-Jin},journal={arXiv preprint arXiv:2603.11460},note={Accepted at CVPR 2026},year={2026},status={published},}
CVPR
SAIL: Similarity-Aware Guidance and Inter-Caption Augmentation-based Learning for Weakly-Supervised Dense Video Captioning
Ye-Chan Kim, SeungJu Cha, Si-Woo Kim, MinJu Jeon, Hyungee Kim, and Dong-Jin Kim
SAIL tackles weakly-supervised dense video captioning through similarity-aware guidance and inter-caption augmentation. The framework reduces reliance on dense temporal annotations while maintaining strong captioning quality.
@article{kim2026sail,title={SAIL: Similarity-Aware Guidance and Inter-Caption Augmentation-based Learning for Weakly-Supervised Dense Video Captioning},author={Kim, Ye-Chan and Cha, SeungJu and Kim, Si-Woo and Jeon, MinJu and Kim, Hyungee and Kim, Dong-Jin},journal={arXiv preprint arXiv:2603.05437},note={Accepted at CVPR 2026},year={2026},status={published},}
2025
EMNLP
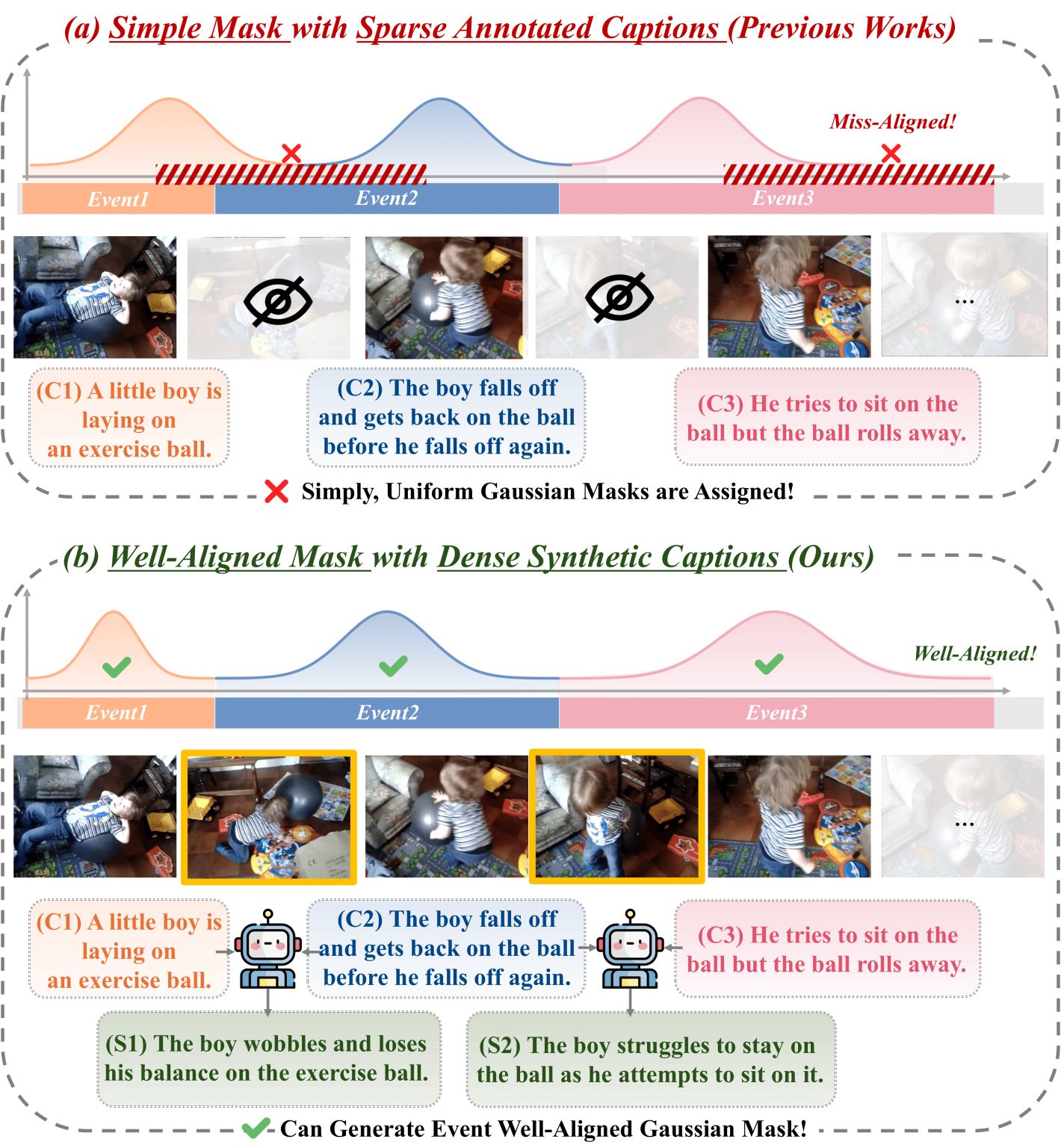
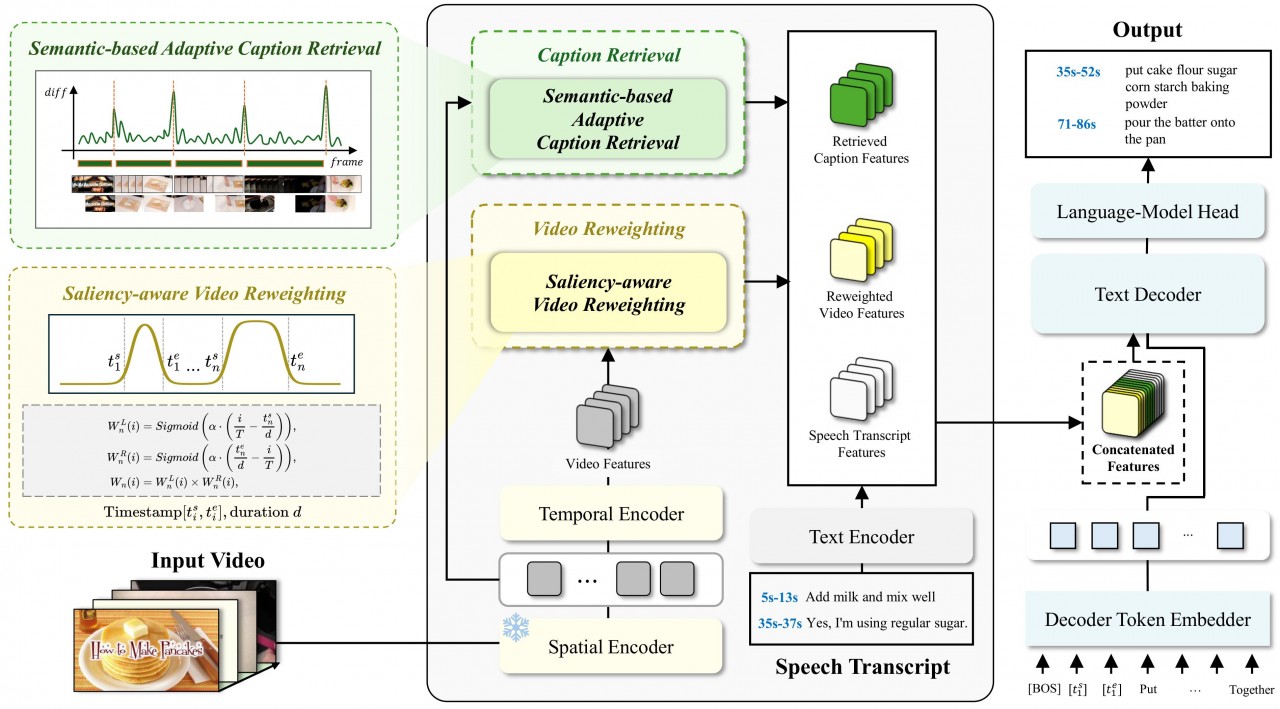
Sali4Vid: Saliency-Aware Video Reweighting and Adaptive Caption Retrieval for Dense Video Captioning
MinJu Jeon, Si-Woo Kim, Ye-Chan Kim, HyunGee Kim, and Dong-Jin Kim
In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
A dense video captioning framework that reweights video frames by saliency and adaptively retrieves relevant captions at inference time. By concentrating supervision on semantically important moments and grounding generation in retrieved context, Sali4Vid produces more accurate and temporally localized descriptions.
@inproceedings{jeon2025sali4vid,title={Sali4Vid: Saliency-Aware Video Reweighting and Adaptive Caption Retrieval for Dense Video Captioning},author={Jeon, MinJu and Kim, Si-Woo and Kim, Ye-Chan and Kim, HyunGee and Kim, Dong-Jin},booktitle={Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing},pages={25788--25801},year={2025},status={published},}
ACM MM
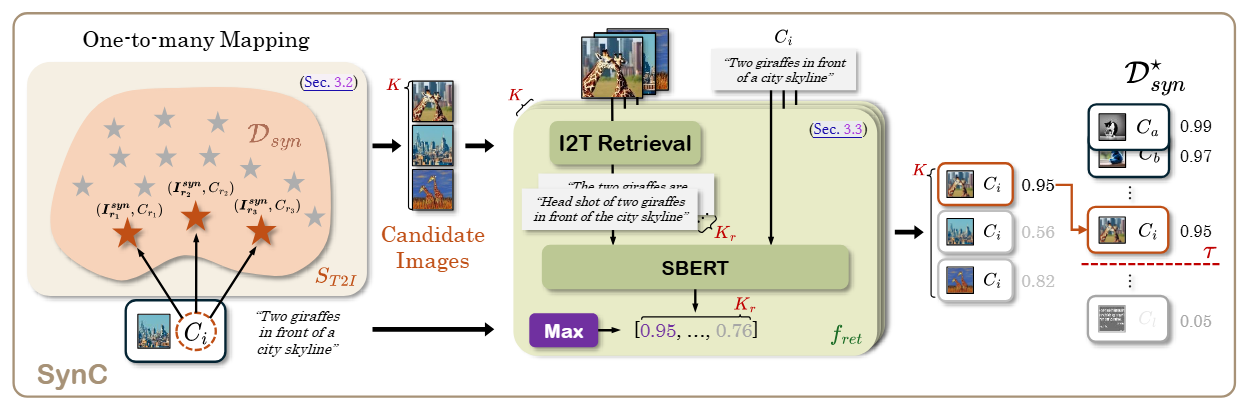
SynC: Synthetic Image Caption Dataset Refinement with One-to-many Mapping for Zero-shot Image Captioning
Si-Woo Kim, MinJu Jeon, Ye-Chan Kim, Soeun Lee, Taewhan Kim, and Dong-Jin Kim
In Proceedings of the 33rd ACM International Conference on Multimedia, 2025
SynC refines noisy synthetic image-caption datasets through a one-to-many mapping that re-aligns each image with its best-matching captions from the generated pool. This data-centric refinement boosts zero-shot image captioning performance without any additional human annotation.
@inproceedings{kim2025sync,title={SynC: Synthetic Image Caption Dataset Refinement with One-to-many Mapping for Zero-shot Image Captioning},author={Kim, Si-Woo and Jeon, MinJu and Kim, Ye-Chan and Lee, Soeun and Kim, Taewhan and Kim, Dong-Jin},booktitle={Proceedings of the 33rd ACM International Conference on Multimedia},pages={2683--2692},year={2025},status={published},}