MinJu Jeon
Hanyang University · Multimodal AI Lab · AI Researcher

At ICCV 2025, Honolulu, Hawaii
Hi! I'm MinJu Jeon, a Master's student in Data Science at Hanyang University, advised by Prof. DongJin Kim, and currently a Research Intern at Naver Cloud, Voice Tech team.
My research centers on Multimodal learning, spanning Vision-language understanding (dense video captioning, text-video retrieval) and Multilingual speech (G2P, text-to-speech). I'm also drawn to Data-centric methods that improve model robustness across modalities and languages.
My research centers on Multimodal learning, spanning Vision-language understanding (dense video captioning, text-video retrieval) and Multilingual speech (G2P, text-to-speech). I'm also drawn to Data-centric methods that improve model robustness across modalities and languages.
News
June 2026Joining LG AI Research as a Research Intern at the EXAONE Lab (Incoming)
Mar 2026Cap4Bridge accepted at IEEE Access 2026
Feb 2026Two papers accepted at CVPR 2026
Dec 2025Started research internship at Naver Cloud, Voice Tech Team
Aug 2025Sali4Vid accepted at EMNLP 2025 (Long, Main)
Background
June 2026 – Incoming

Research Intern, LG AI Research · EXAONE Lab
Incoming
Incoming
Dec 2025 – Present

Research Intern, Naver Cloud · Voice Tech Team
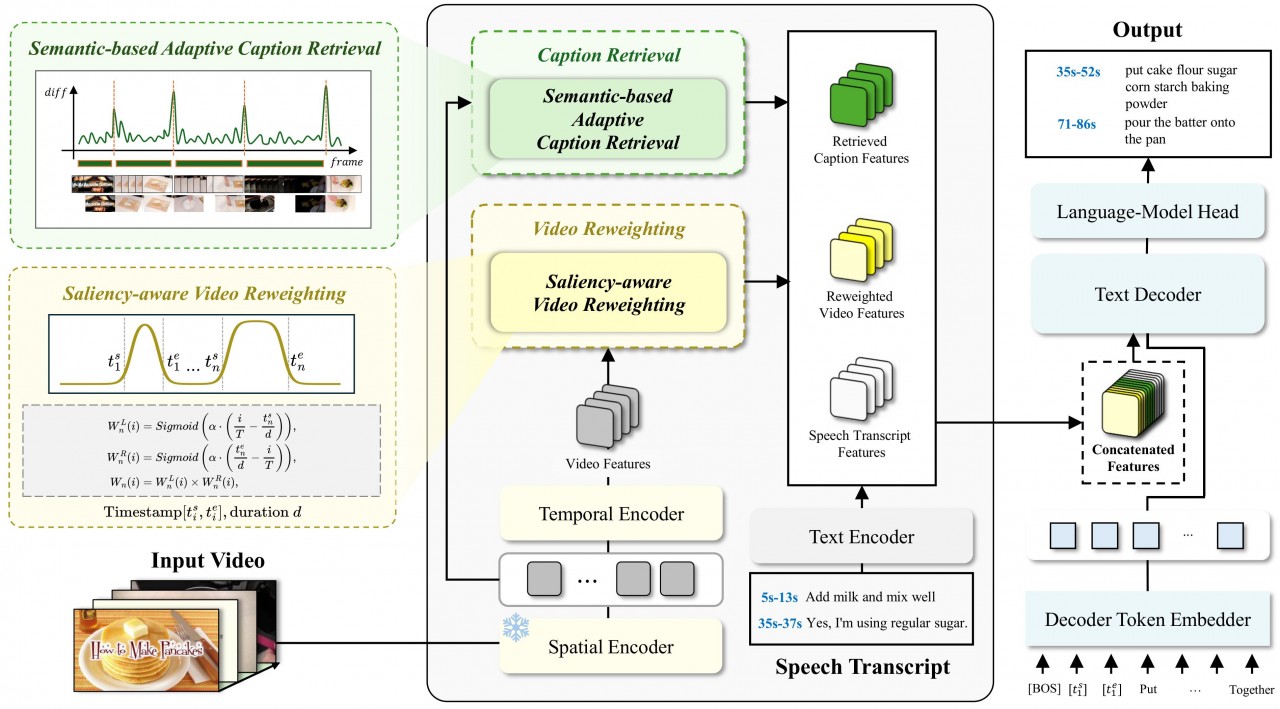
Multilingual G2P & robust TTS for non-canonical text
Multilingual G2P & robust TTS for non-canonical text
Sep 2024 – Present

M.S. in Data Science, Hanyang University
Mar 2020 – Aug 2024
B.S. in Industrial Engineering, Hanyang University