MinJu Jeon
Hanyang University · Multimodal AI Lab · AI Researcher

Hi, I'm MinJu Jeon — a Master's student in Data Science at Hanyang University, currently a Research Intern at Naver Cloud(Voice Tech). I work on problems at the intersection of language and perception: multilingual speech (G2P/TTS), video-language understanding, and the messy data work that makes models actually usable in production.
Multimodal Learning Video-Text Retrieval Speech & Language Data-Centric AI
News
Mar 2026Cap4Bridge accepted at IEEE Access 2026
Feb 2026Two papers accepted at CVPR 2026
Dec 2025Started research internship at Naver Cloud, Voice Tech Team
Aug 2025Sali4Vid accepted at EMNLP 2025 (Long, Main)
Background
Dec. 2025 – now
Research Intern, Naver Cloud · Voice Tech Team
Multilingual G2P & robust TTS for non-canonical text
Multilingual G2P & robust TTS for non-canonical text
Sep. 2024 – now
M.S. Data Science, Hanyang University
March 2020 - Aug. 2024
B.S. Industrial Engineering, Hanyang University
selected publications
- EMNLP
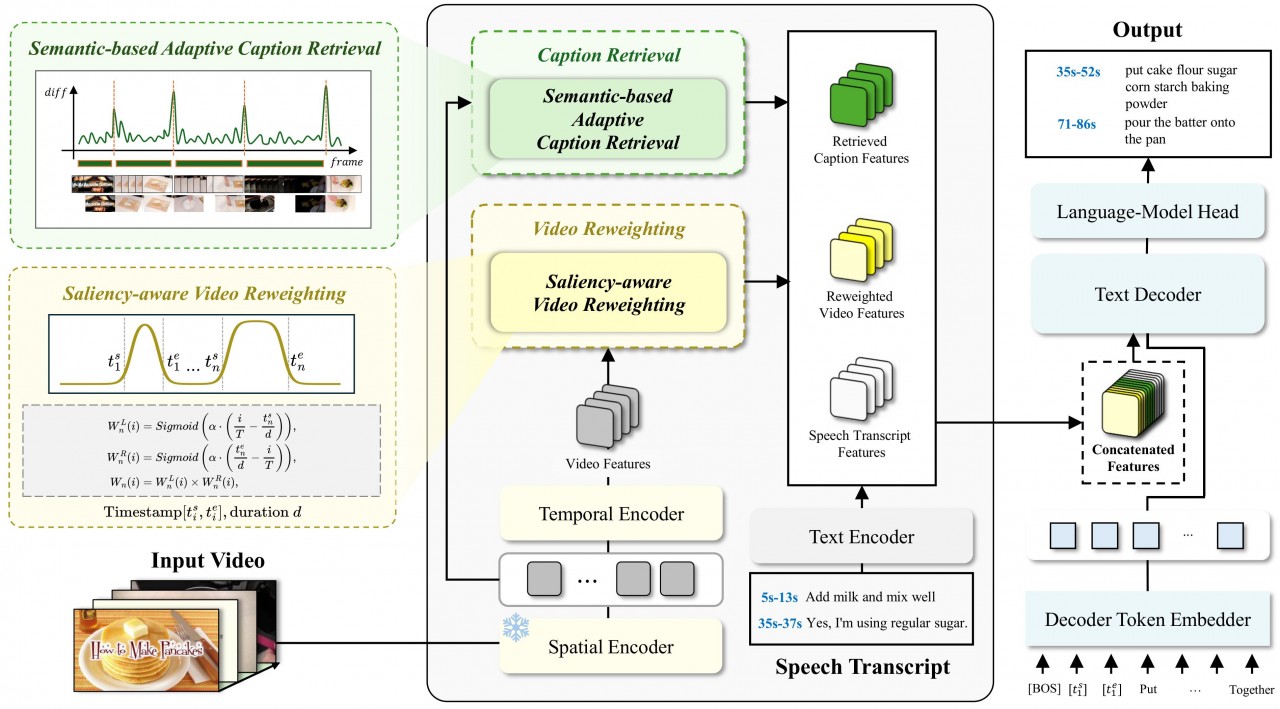 Sali4Vid: Saliency-Aware Video Reweighting and Adaptive Caption Retrieval for Dense Video CaptioningIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
Sali4Vid: Saliency-Aware Video Reweighting and Adaptive Caption Retrieval for Dense Video CaptioningIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025 - IEEE AccessCap4Bridge: Caption-Guided Cross-Modal Contextualization with Stochastic Augmentation for Text-Video RetrievalIEEE Access, 2026
- ACM MM
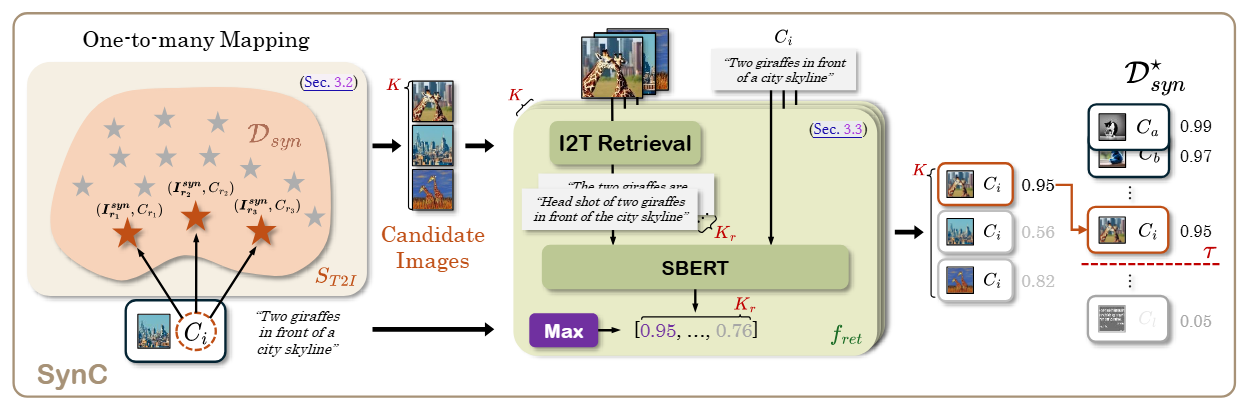 SynC: Synthetic Image Caption Dataset Refinement with One-to-many Mapping for Zero-shot Image CaptioningIn Proceedings of the 33rd ACM International Conference on Multimedia, 2025
SynC: Synthetic Image Caption Dataset Refinement with One-to-many Mapping for Zero-shot Image CaptioningIn Proceedings of the 33rd ACM International Conference on Multimedia, 2025 - CVPR
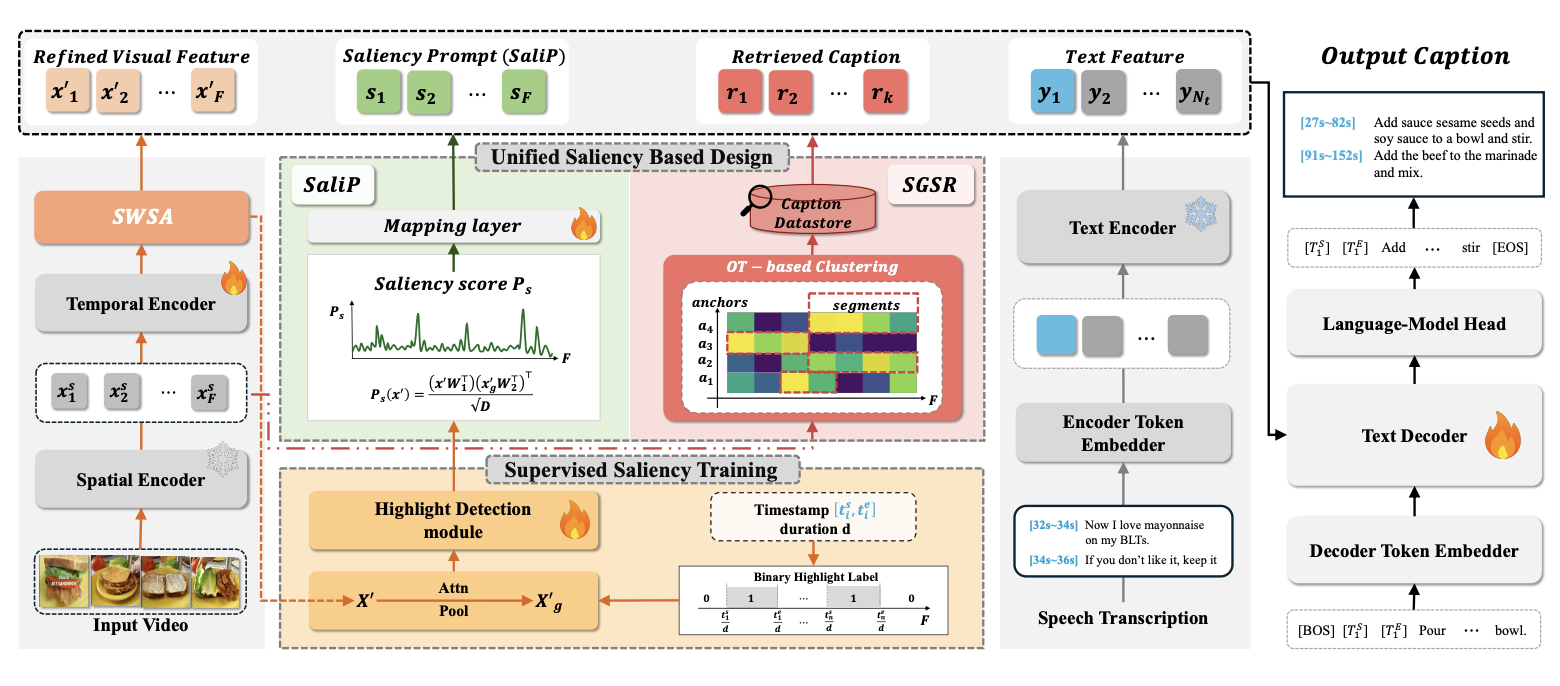 Follow the Saliency: Supervised Saliency for Retrieval-augmented Dense Video CaptioningarXiv preprint arXiv:2603.11460, 2026Accepted at CVPR 2026
Follow the Saliency: Supervised Saliency for Retrieval-augmented Dense Video CaptioningarXiv preprint arXiv:2603.11460, 2026Accepted at CVPR 2026 - CVPR
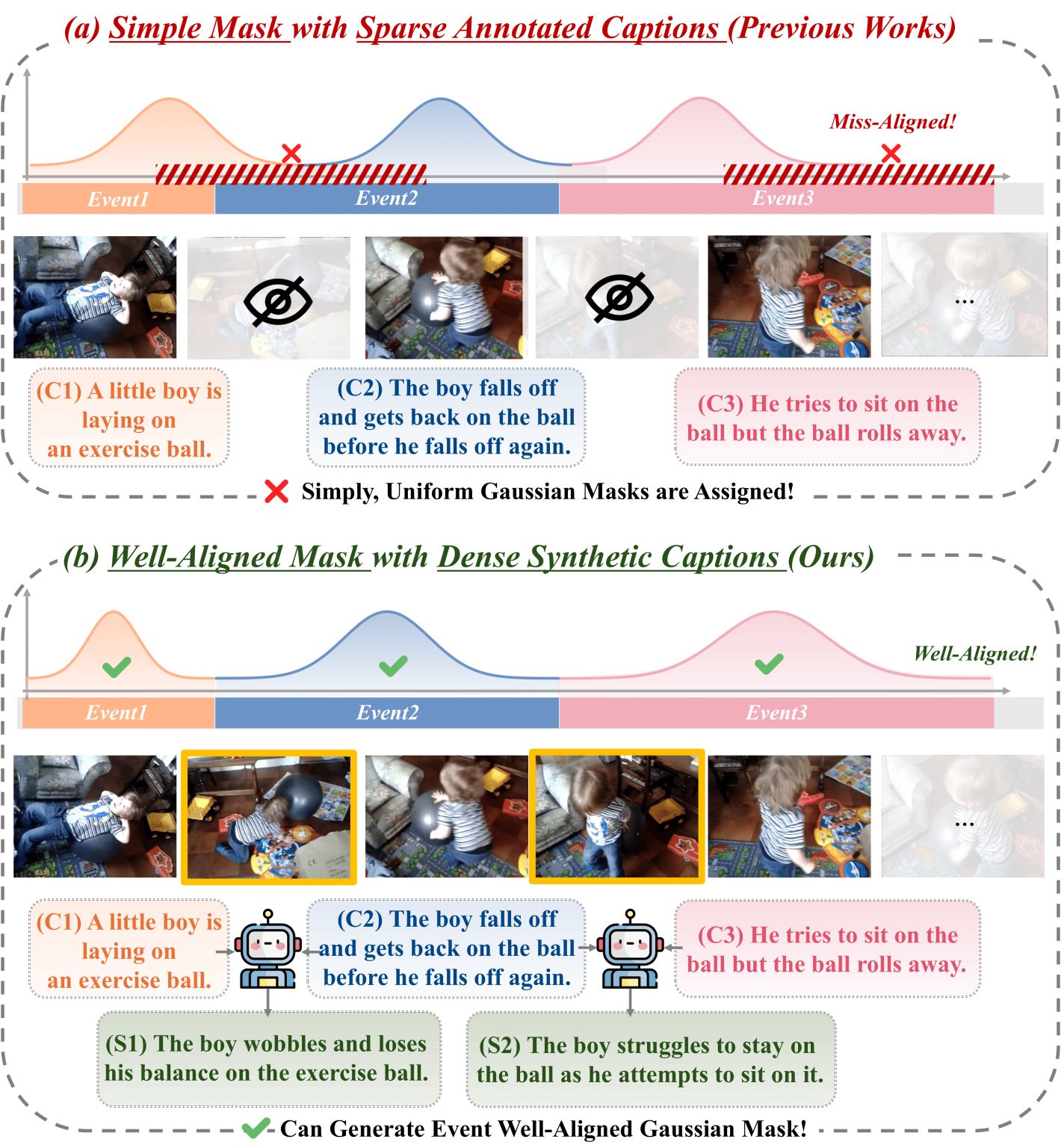 SAIL: Similarity-Aware Guidance and Inter-Caption Augmentation-based Learning for Weakly-Supervised Dense Video CaptioningarXiv preprint arXiv:2603.05437, 2026Accepted at CVPR 2026
SAIL: Similarity-Aware Guidance and Inter-Caption Augmentation-based Learning for Weakly-Supervised Dense Video CaptioningarXiv preprint arXiv:2603.05437, 2026Accepted at CVPR 2026